

Table of Contents
If you have ever used the GNOME desktop for any length of time on any weak or underpowered laptop, you might have run into some performance issues. The main problem you will have noticed, though, is probably that the animations were not smooth, and there was a lot of noticeable lag in them.
While the GNOME desktop has undergone many performance optimizations during the past few years, the real root cause of the issue was solved just a few days ago with the introduction of the triple buffering functionality in Mutter.
As usual, though, let's take a step back first.
What is triple buffering?
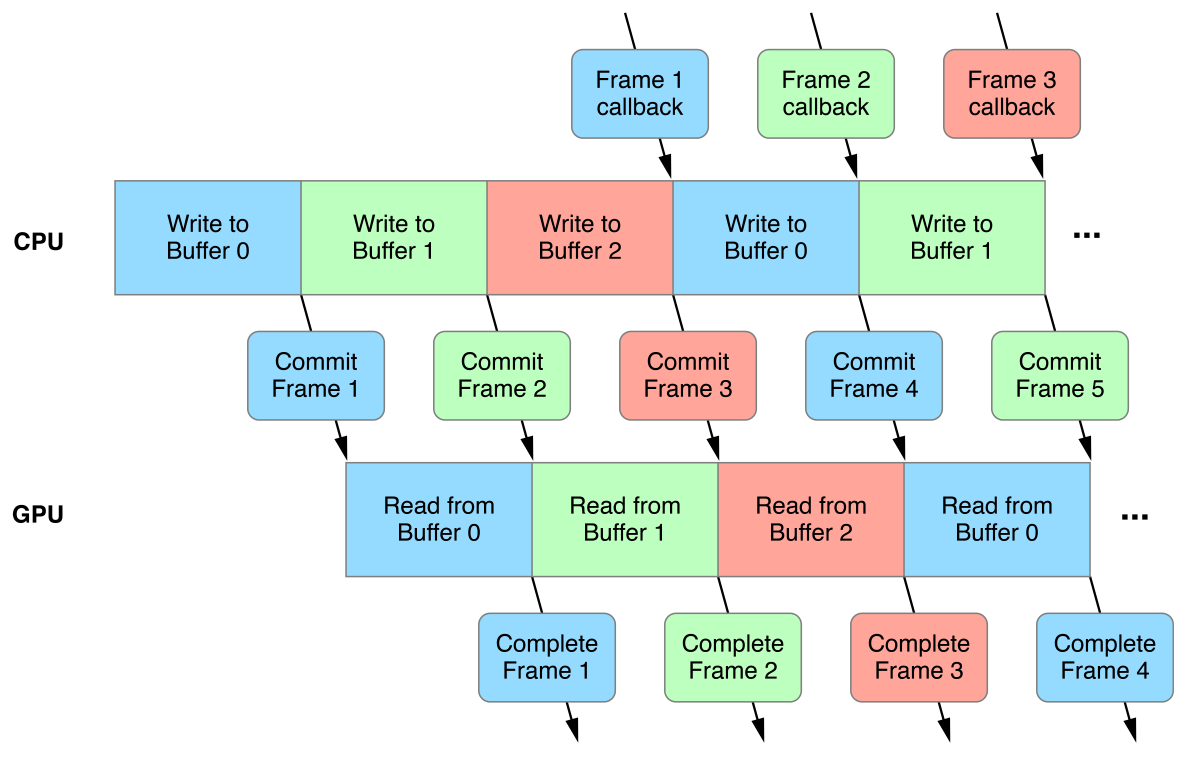
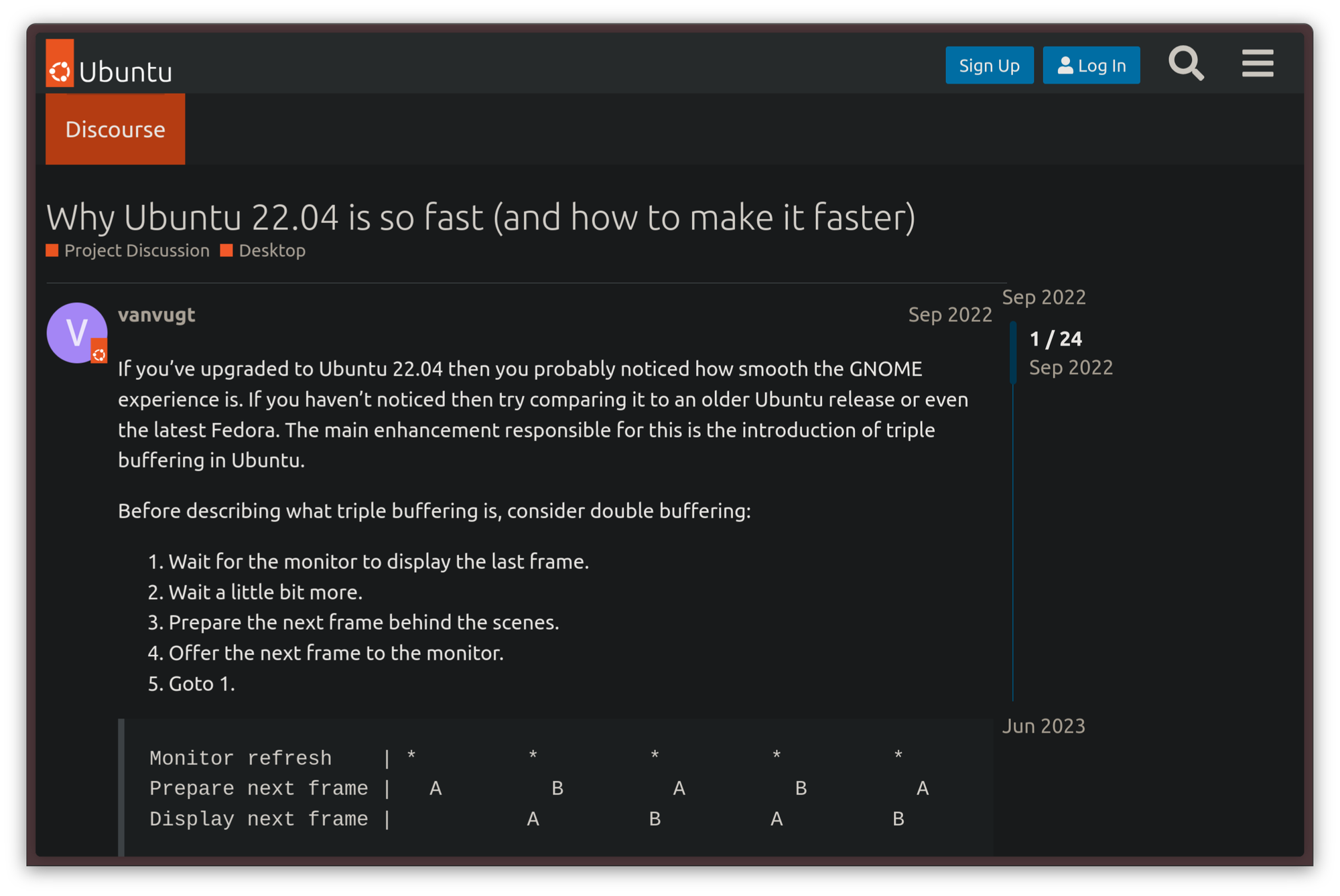
Triple buffering is a common trick in the book of pretty much every OpenGL implementation. When triple buffering is used for graphics rendering, rather than rendering the entire graphical pipeline on one buffer, three buffers are allocated in RAM and used in parallel. These buffers are allocated as follows, according to Intel's documentation:

- The writer thread uses one buffer to store the pixels that will be part of the frame as input
- The reader process listens on the second buffer which reads the pixels the frame is made of from the memory
- The third buffer is used as a spare, which allows the input and output threads to swap their buffers asynchronously.
The advantage of this approach is that the graphical output tends to be smoother because the GPU can begin rendering the next frame without necessarily waiting on the two main front and back buffers to be done with the current transaction. The third, spare buffer, can be used to calculate a new frame early. The only real drawback of this approach is that, in some implementations, it causes latency.
This technique is already widely used in plenty of video games, as it comes free with every modern OpenGL implementation. The only reason why GNOME didn't use it yet lies in some Mutter architectural quirks.
Let us now move on and talk about what happened to GNOME itself.
Triple buffering and GNOME
Going back to GNOME. Remember how we talked about the problem with slow and laggy animations earlier? Well, the entity that led the efforts to find and resolve the root cause that caused this symptom was none other than Canonical, the company behind Ubuntu Desktop.

Canonical contributing heavily to GNOME is nothing new: since the Unity desktop was abandoned in favor of GNOME starting from the release of Ubuntu 17.10, Canonical has become a very important contributor to the GNOME ecosystem, consistently contributing upstream in meaningful ways, and working together with the GNOME team to bring Ubuntu users a Canonical-branded GNOME experience with the Yaru theme in a such a way that existing GTK applications that rely on the Adwaita theme would not break on Yaru.
Particularly, Canonical's focus has been on improving the performance of the GNOME interface — so, there is no surprise that the work on triple buffering was led by them. Collaboration wins, at the end of the day, and when multiple distros standardize on the same set of desktop environments, good things come out of it. Just think of all the good that came to KDE Plasma after Valve decided to use it on the Steam Deck: while not directly comparable, this is a similar story.
How Canonical found out
While it has been known for a while that the GNOME desktop suffered from some performance issues, the root of the issue was identified in more rigorous tests around 2020. The Ubuntu team was playing around with GNOME, trying to experiment with further eye candy, when they found out that, the more eye candy they added, the more the shell would slow down. What's more puzzling was that the cause of the lag did not appear to be inadequate computational power on the machines where the lag happened — on the contrary, the hardware was perfectly capable, but the GPU was under-utilized while the lag occurred.
The root cause of the problem was identified to be in the way Mutter renders its frames. Rather than using triple-buffering, it runs all the rendering into a single-threaded loop, which, by design, has a very limited throughput. It was apparent from there that this was the limitation to work around to help with the performance concerns.
Initially, work on making the rendering event loop multithreaded with a triple-buffered architecture started with the X11 session and frame clock changes. That initial part of the work was the more manageable part since it came free by relying on GLX — an X11 protocol that bridged the gap between X11 itself and OpenGL graphical APIs — which is also triple-buffered.
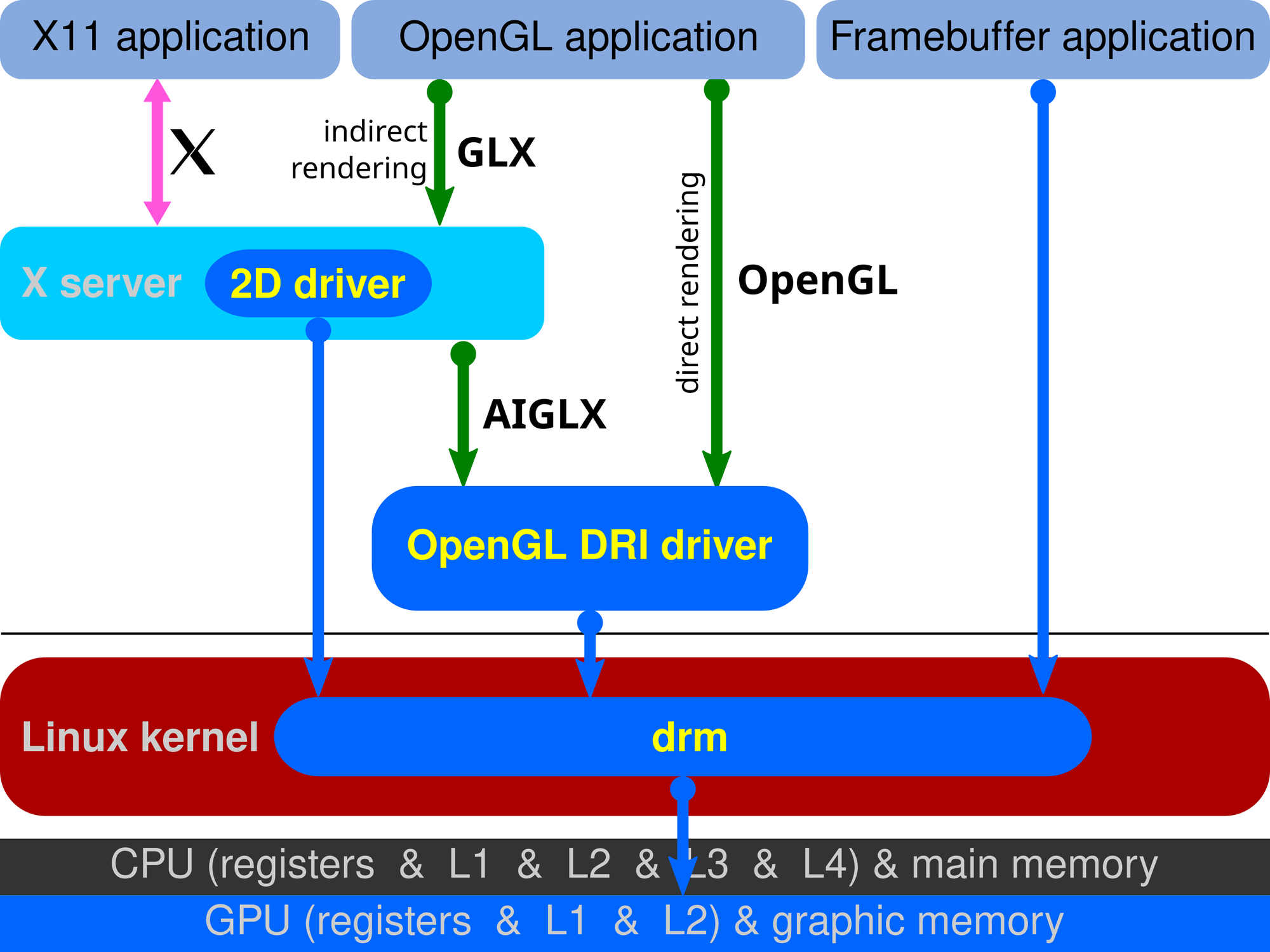
The limitation with that implementation was, of course, the fact that it was limited. GLX is an X11-specific extension: it is, hence, not portable to Wayland. For tasks that used to require GLX, modern Wayland implementations use EGL, a different API, instead. Besides, rather than being based on a client-server architecture like X11, Wayland is just a protocol implemented by compositors, such as GNOME's Mutter. Porting this fix over to Wayland would involve dealing with actual Mutter code, with no shortcuts.
From late 2020 up to early 2022, Canonical worked on implementing triple-buffered rendering on the Wayland backend. A higher-effort rework to Mutter's architecture had to be done to achieve the same result, to make Mutter able to cope with multiple frames in-flight simultaneously. What this means is that, fundamentally, the compositor needs to constantly be one step ahead. Before the GPU is done carrying out the work on rendering the previous frame, the CPU has to already be working on the next one. This works well because the CPU and the GPU are separate entities and, in a standard non-GPGPU architecture, all the GPU does is take orders from the CPU, which acts as the central orchestrator of the entire operation.
At that point, the work had reached a point where it was stable enough that, while upstream GNOME had not accepted it yet, the result started to be shipped in Canonical's own Ubuntu Desktop 22.04 LTS. You should know that Ubuntu does not ship a copy of GNOME that is exactly, 1 on 1 the same as upstream GNOME, but several downstream patches are applied to it by Canonical and Debian. What this means for those of you who are running Ubuntu is that you have been enjoying the fruit of this labor for the past two or three years - while, by default, that was not true for other distros.
At last, in 2025, here we are. The patch has been accepted by GNOME and it has made it into GNOME 48, where it will bring a fundamental performance improvement to all distros.
It needs to be specified that the extent of the performance improvement varies between various hardware configurations. However, it never makes things worse, and it is only a range between a slight and a noticeable improvement. As usual, by the time GNOME merges a merge request, it manages to be mature enough that no regressions are introduced by adding it.
But what about latency?
Those of you who are more keen on competitive online games will have been asking themselves: “will this not increase the input lag”?
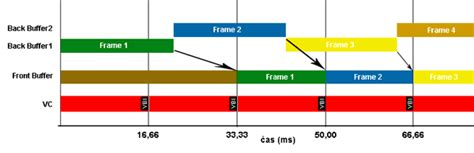
The answer is, in short, no — not in this implementation. Differently from most triple-buffering implementations that are found in games, this one sticks to double buffering in all cases, unless when the system is unable to deliver the expected performance, and then, only then, does the algorithm naturally transition to triple buffering.
Trying to make it simpler - triple buffering is only ever used when it is truly needed. This is a big part of the reason why this implementation does not regress and does not make things worse on existing hardware. If you have been happy with the standard behavior, and your system always renders GNOME animations at your monitor's frame rate, then you don't have to worry about it: odds are, the triple-buffered rendering behavior will never, or very seldom, get triggered on your device. If that is not the case, though, triple buffering will just come in clutch whenever your system cannot keep up — giving you a subjectively smoother experience, all things considered.
So, are we done?
According to Canonical — no, not really. Implementing triple buffering at the compositor level is a great milestone, but it is not quite the be-all-end-all. Several applications still need to do some work themselves to enable triple buffering and reap the full benefits from it. For example, Canonical notes it seems like Firefox struggles to render the first few frames of the touchpad scrolling physics when flung with a touchpad smoothly, unless the machine is set to performance mode. There is nothing your Wayland compositor can do about this issue — it is wholly Firefox's domain here, and they are expected to come up with a comparable solution to work around this limitation eventually, just like GNOME and Canonical did for Mutter.
So, are there any limitations?
While triple buffering seems to be overwhelmingly good news, yes, there are sadly some limitations to this approach. The main one is that… you guessed it. Come you, you did. If your system is running an NVIDIA GPU, odds are you will not be reaping the full effects of this performance improvement. The reason is that the NVIDIA driver is, as always, very different from standardized mesa implementations, and only supports explicit sync — which is completely synchronous — whereas every other GPU driver also supports implicit sync — which is asynchronous. When implicit sync is supported, you can pass buffers around without waiting until the GPU is done rendering them, which can result in a healthy performance speed-up, and is essential for this patch to work well. Since NVIDIA does not support this, however, you will not be getting the same level of performance on those cards. You should probably read Xaver's article on Explicit Sync to know more.
One rare limitation is that users who run Linux on a virtual what machine with software rendering will only get some benefit from this implementation, but not nearly as much as non-NVIDIA physical GPUs will. Besides, Canonical recommends running desktop environments that do not rely on any graphical APIs like OpenGL at all on sessions without graphical acceleration whatsoever, since it is more expensive for a CPU to emulate a GPU with llvmpipe than it is to run a non-accelerated graphical session.







{kind=link}