

Table of Contents
A while ago, I published an article explaining how AI scrapers were placing a heavy burden on Open Source projects; though that is still true, some tools have been developed to address that (such as Anubis).
Even earlier, we talked about whether Open Source projects should allow AI code contributions or AI-generated bug reports. Many projects, such as Servo, decided not to allow them at all.

However, things are moving, and these discussions are taking place increasingly more often. Thus, I'd like to briefly address the question: how are Linux and the FOSS ecosystem dealing with AI?
Let's start with this article by ZDNET. They claim that AI is "creeping into the Linux kernel - and official policy is needed ASAP".

An example of that is AUTOSEL, which is a "Modern AI-powered Linux Kernel Stable Backport Classifier".
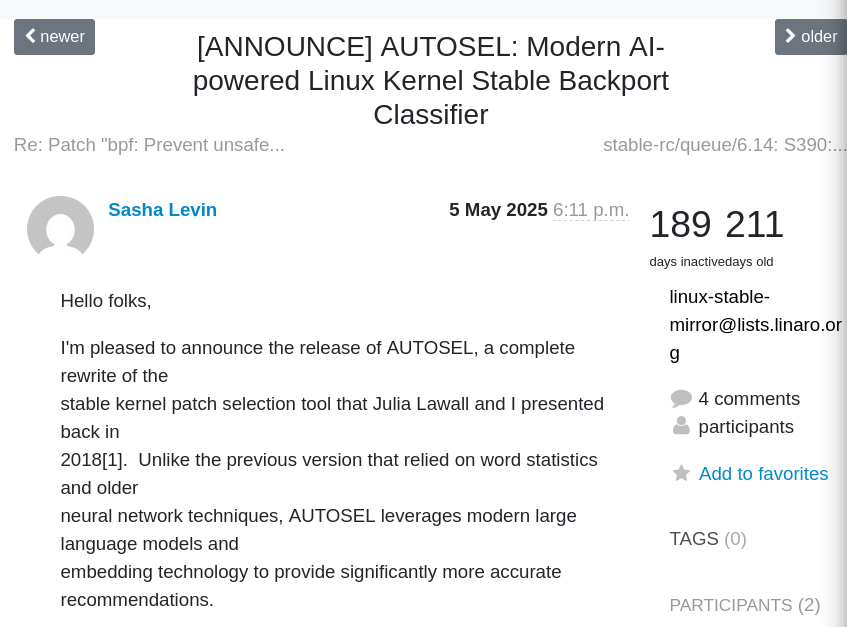
According to the announcement,
AUTOSEL automatically analyzes Linux kernel commits to determine whether they should be backported to stable kernel trees. It examines commit messages, code changes, and historical backporting patterns to make intelligent recommendations.
This has been praised as a positive example of modern LLM usage, as it's meant to support a developer without replacing one; and it does not perform any action, as it only presents advice with a reasoning for it, and it's up to the developer whether to take it or not.
However, AI usage in the kernel goes beyond the use of such tools.
During the 2025 Open Source Summit, NVIDIA Developer Sasha Levin shared that a patch that was credited to him was entirely AI-generated, though he did review and test it himself.
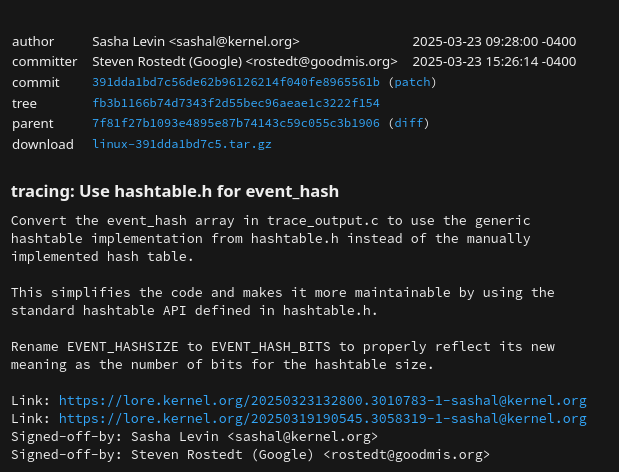
Note that this was not disclosed when the patch was submitted for review, at least to my knowledge.
Please note that AI agents are used here, meaning that the LLM is allowed to run git commands to learn about the repositories; though, I'm assuming that the access is read-only for them.
Another example is the git-resolve script that will "resolve an ambiguous ID into a full commit"; this was also fully generated, and it included a set of testcases, which is unusual for kernel scripts.
AI code in the kernel includes some particularly sensitive work. In early 2024, the kernel took on the responsibility of assigning Common Vulnerabilities and Exposures numbers. This began as a collection of bash scripts, but it quickly grew unmaintainable; the team decided to use an LLM to translate those scripts to Rust, making CVE assignment code entirely AI-generated.

This raised many questions, even just during Levin's presentation: isn't there a risk of trusting LLM outputs too much? What's the licensing of AI-generated content?
Levin believes that if an LLM produces code, he is free to make use of it. This is somewhat debatable, as some complex legal issues depend on the country you live in, but this could be the topic of an entire other article.
He's not the only one experimenting with this. Another example are these patches by Kees Cook, who was experimenting to see how much code he could reasonably generate.
Turns out, he had success with some reasonable unit tests, which - he claims - saved him some time, though some prompting was required to nail it. However, he did not manage to save any time on non-testcase patches.
Shortly after his talk, Levin sent a Request For Comments set of patches to introduce AI coding assistant configuration files to the Linux kernel documentation.
Specifically, this consisted of two different patches.
The first patch adds unified configuration files for various AI coding assistants (Claude, GitHub Copilot, Cursor, Codeium, Continue, Windsurf, and Aider). These are all symlinked to a central documentation file to ensure consistency across tools.
The second patch adds the actual rules and documentation that guide AI assistants on Linux kernel development practices, including:
- Following kernel coding standards
- Respecting the development process
- Properly attributing AI-generated contributions
- Understanding licensing requirements
Interestingly enough, the AI is instructed to add itself as the co-author of all patches, but to only let a human sign off the commit, as that "represents a legal certification".
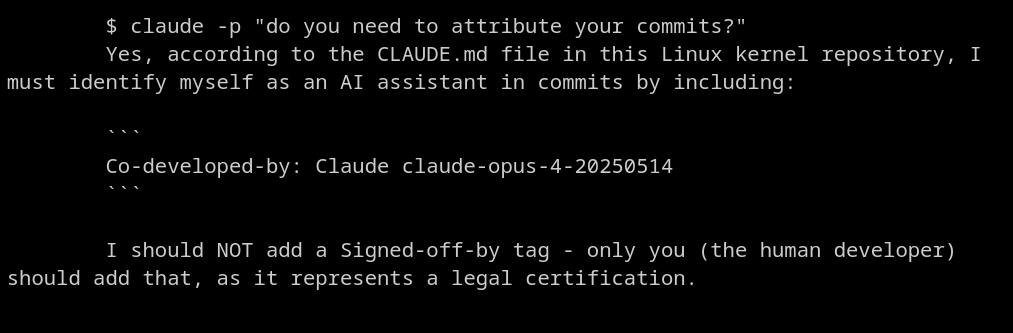
Along with this documentation for AI agents, there is a patch being reviewed to introduce guidelines for human developers using AI.

Please note that these guidelines only apply when a significant portion of the patch content is generated; smaller tweaks, such as spelling and grammar fixes, variable renamings, reformattings, etc. are out of scope.
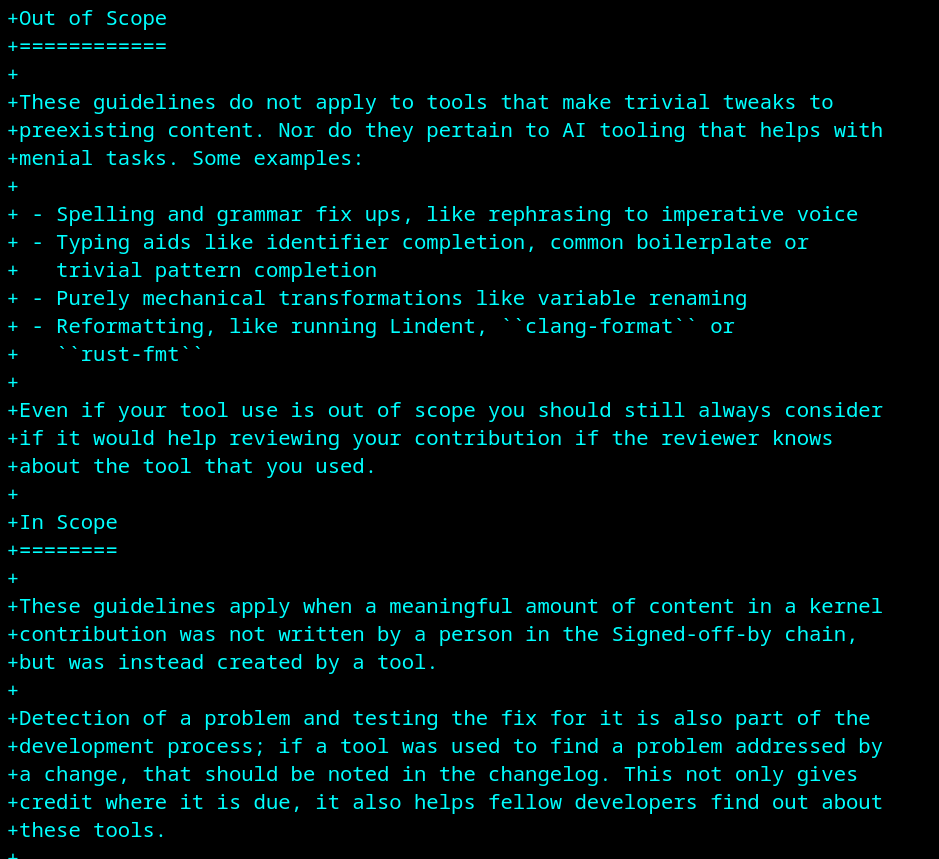
The guidelines ask to disclose which tools were used, the input of those tools (such as the prompts you chose), and which content exactly was AI-generated.
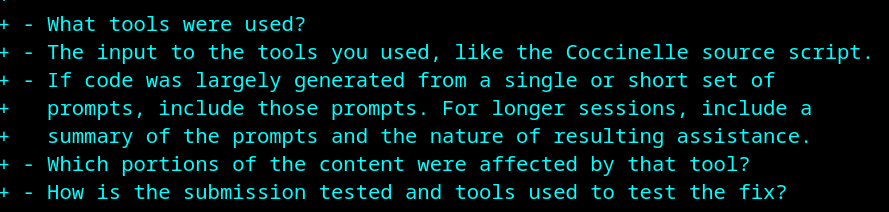
It's then up to the maintainers to choose what to do with that information. They might want to reject the patch outright, review it more carefully, suggest a better prompt, or just ask for more details. (Though I'm a bit worried about this creating very different policies within the kernel.)

The Great™ Linus Torvalds has, of course, commented on this proposal as well; here's what he had to say:
Honestly, I think the documented rule should not aim to treat AI as anything special at all, and literally just talk about tooling. [...] IOW, this should all be about "tool-assisted patches should be described as such, and should explain how the tool was used". [...] people should mention the tool it was done with, and the script (ok, the "scripts" are called "prompts", because AI is so "special") used.
I would like to quickly mention that the Linux Foundation also has its own rules for the usage of generative AI tools. As a quick reminder, the work of the Linux Foundation goes well beyond Linux kernel development, as it also sponsors and works on hundreds of open-source projects.
The Linux Foundation only puts two rules on AI-generated content. Firstly,
Contributors should ensure that the terms and conditions of the generative AI tool do not place any contractual restrictions on how the tool’s output can be used that are inconsistent with the project’s open source software license, the project’s intellectual property policies, or the Open Source Definition.
These seem to be in line with the question we asked earlier: what's the exact license of content generated by AI? Since, again, the answer is not easy to obtain, the Linux Foundation seems to have this policy to, well, blame the developer if anything goes wrong.
The second term is the following:
If any pre-existing copyrighted materials (including pre-existing open source code) authored or owned by third parties are included in the AI tool’s output, prior to contributing such output to the project, the Contributor should confirm that they have have permission from the third party owners–such as the form of an open source license or public domain declaration that complies with the project’s licensing policies–to use and modify such pre-existing materials and contribute them to the project.
This rule exists because LLM models have been found to generate exact excerpts of their training data in a small number of cases. This means that the developer should always check that the generated code does not contain any copyrighted material (though it's unclear how they would do that).
Well, these were the Linux Kernel and the Linux Foundation, both of which are very big institutions within the FOSS world, and they are worked on by companies such as NVIDIA itself; I'm not surprised to see active work on how to use AI tools here.
But of course, the rest of the FOSS world is often a bit more hostile.
I already mentioned how Servo, the web engine currently developed by the Linux Foundation, entirely bans AI contributions. This is due to claims of maintainer burden, (lack of) correctness of these patches, and the above-mentioned copyright issues.

Multiple GNOME projects also have such a guideline, though I'm currently not aware of a project-wide stance on this. ElementaryOS does have one (which is directly inspired by GNOME's). Some goes for FreeBSD and Gentoo.
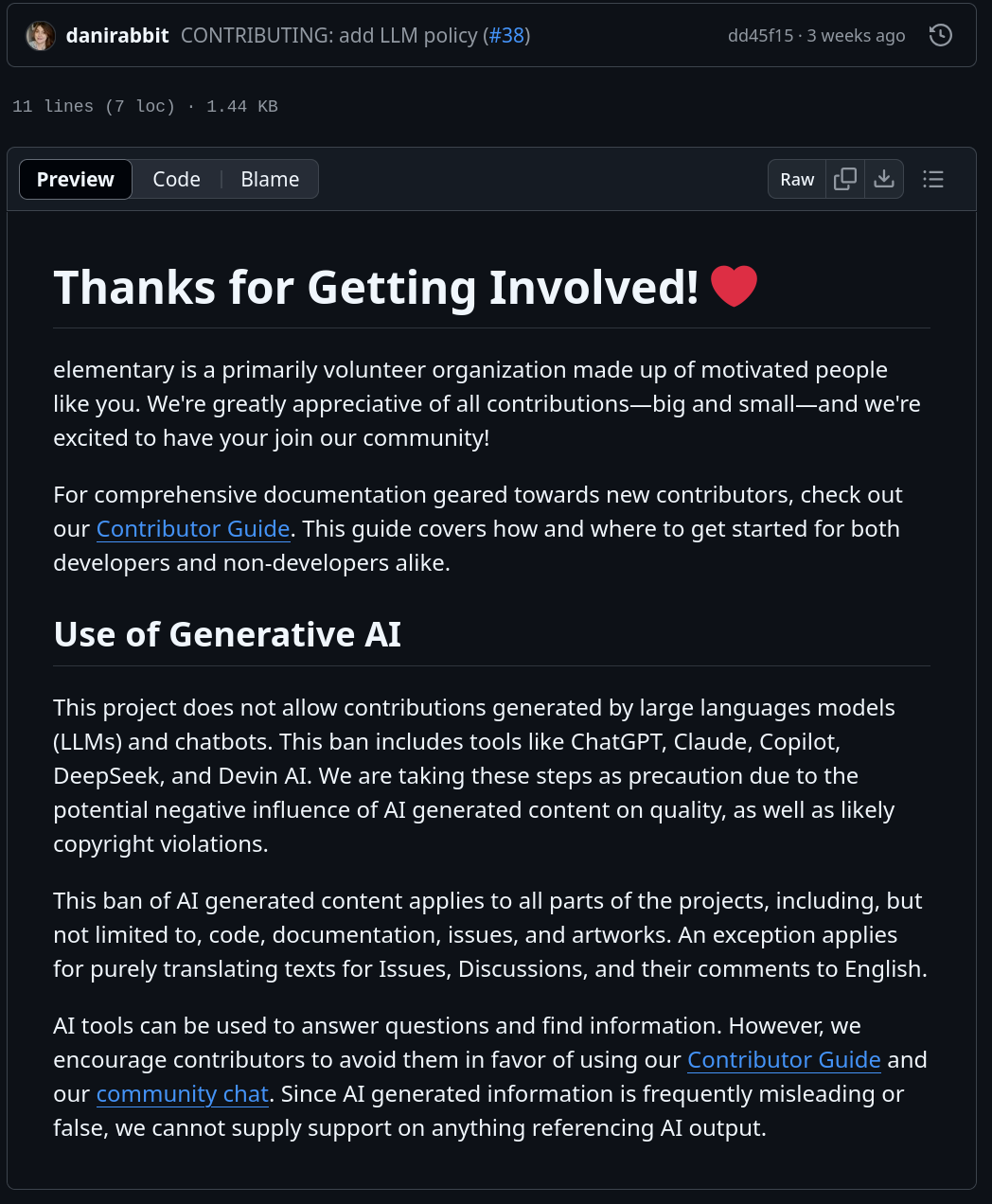
I can also share that there has been some internal discussion within KDE on what a policy on AI contributions should look like. This was started by one patch that was submitted by developer Mikhail Sidorenko, which was generated by Cursor.

Other projects have a more "moderate" policy, which is more akin to the Kernel one.
One such example is Fedora, which does allow for AI assistance, but requires the developer to follow some principles.

Namely, you (1) take responsibility for your contribution, regardless of how you made the patch. (2) You must disclose the usage of AI tools; the recommended method is to use the Assisted-by commit message trailer. (3) You must use AI as a tool to assist you; it should not be "the sole or final arbiter in making judgment on a contribution".

This brings me to Mozilla, which has recently been under fire for reportedly "pivoting to AI" (I'll make an example later).
They have guidelines that seem to be even more permissive of AI usage than the Linux kernel's, as they only place one real constraint on these contributions: you are accountable for all changes you submit, regardless of the tools you use.

Now, a few weeks ago, Firefox published a blogpost titled "Introducing AI, the Firefox way: A look at what we're working on and how you can help shape it".
According to them, they are making sure to protect your privacy by only running local models on your device, which means that no data leaves your machine. (More on this soon.)

They integrate Generative AI in many different places:
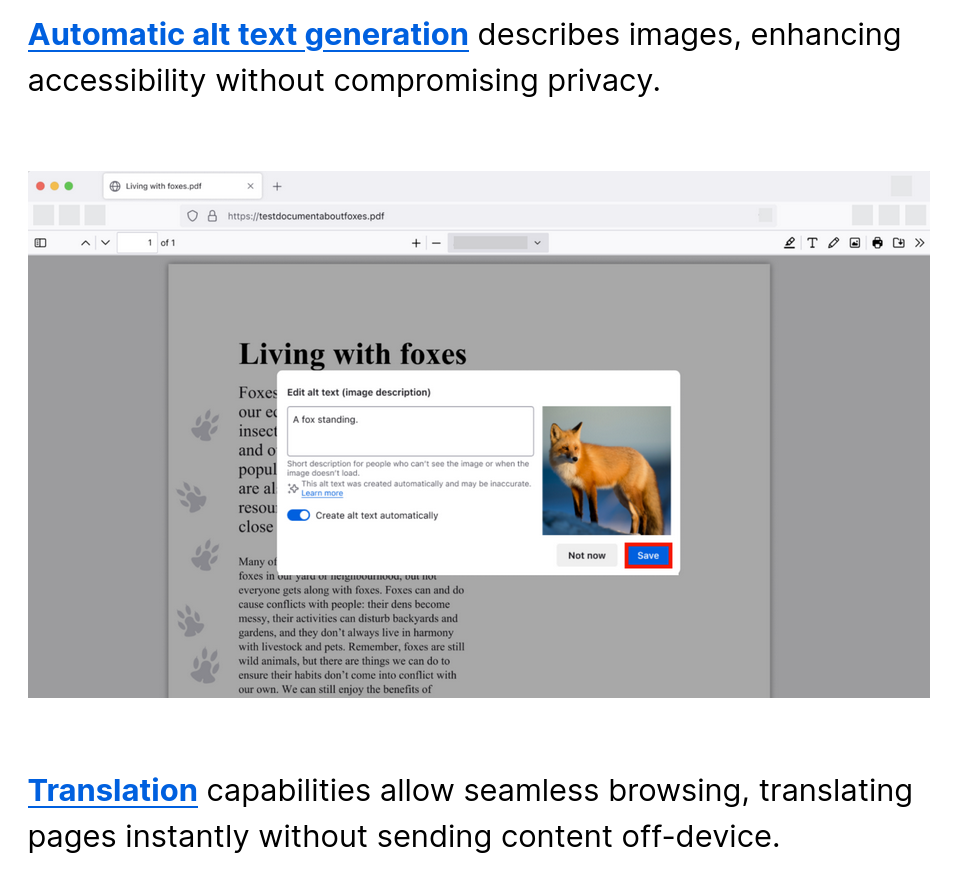
There's automatic alt text generation for images, which helps out with accessibility, and automatic translation of webpages.
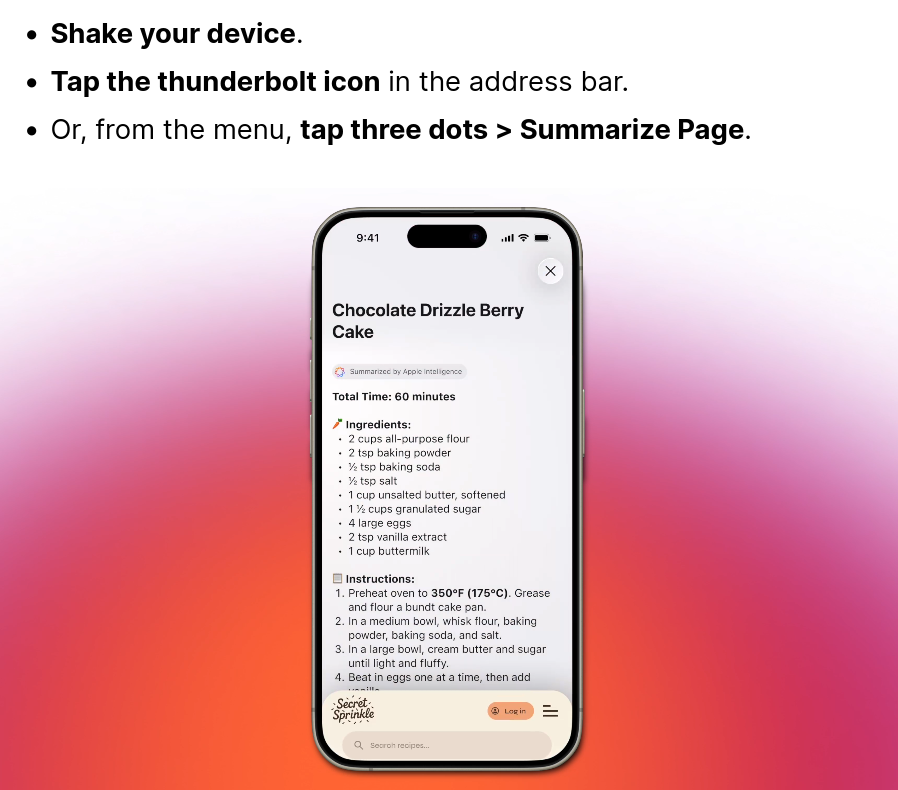
On iOS, you can even shake your device to summarize the page you're viewing (this feature is also supported on the desktop, obviously).
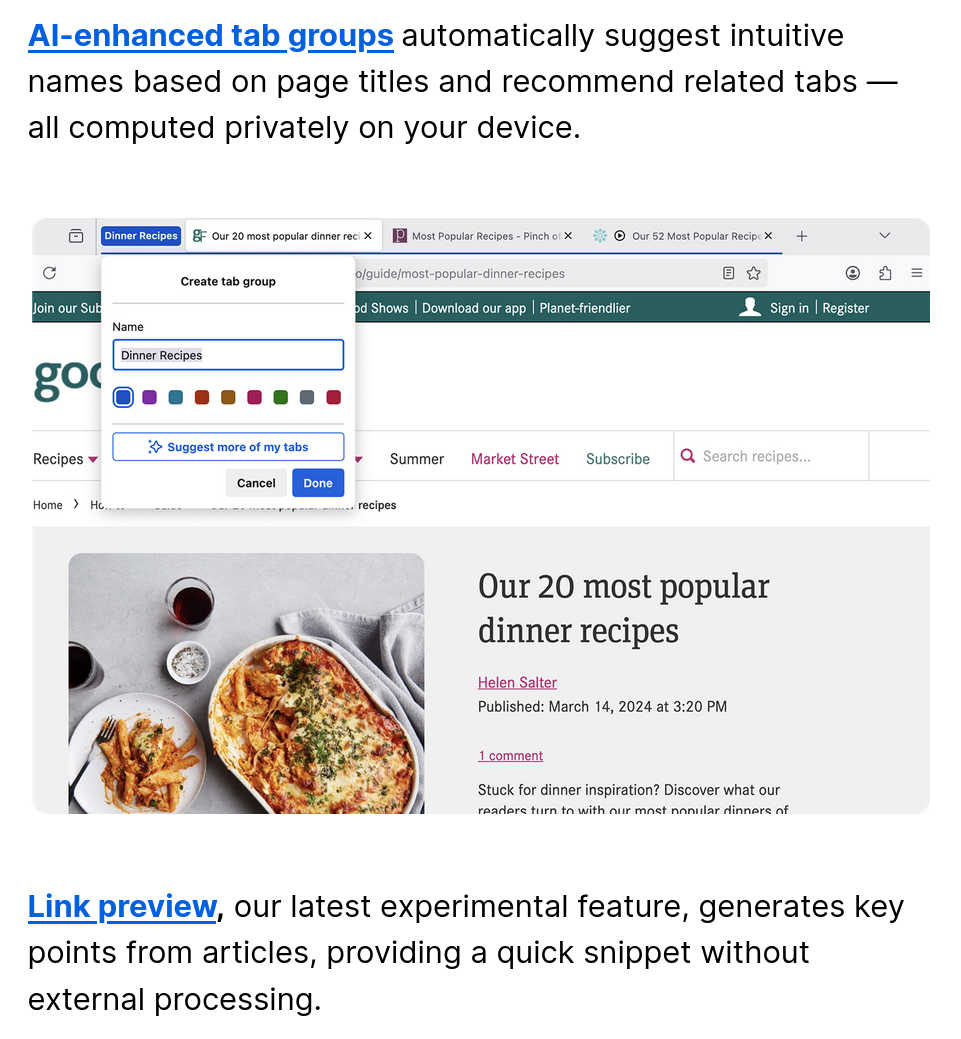
They're also experimenting with AI suggestions for tab groups: if you have a lot of tabs of a similar topic and try to create a tab group, Firefox will suggest a proper name automatically. There's also Link preview, which will show you a snippet from a link you're hovering over.
You are also given the option to have a sidebar with a direct link to a chatbot (which could be any, from Claude to Gemini, and even Mistral). For obvious reasons, however, this feature can not run locally and requires you to accept the privacy policy of the selected chatbot. Effectively, it's a bit like a pinned webpage with that chatbot.
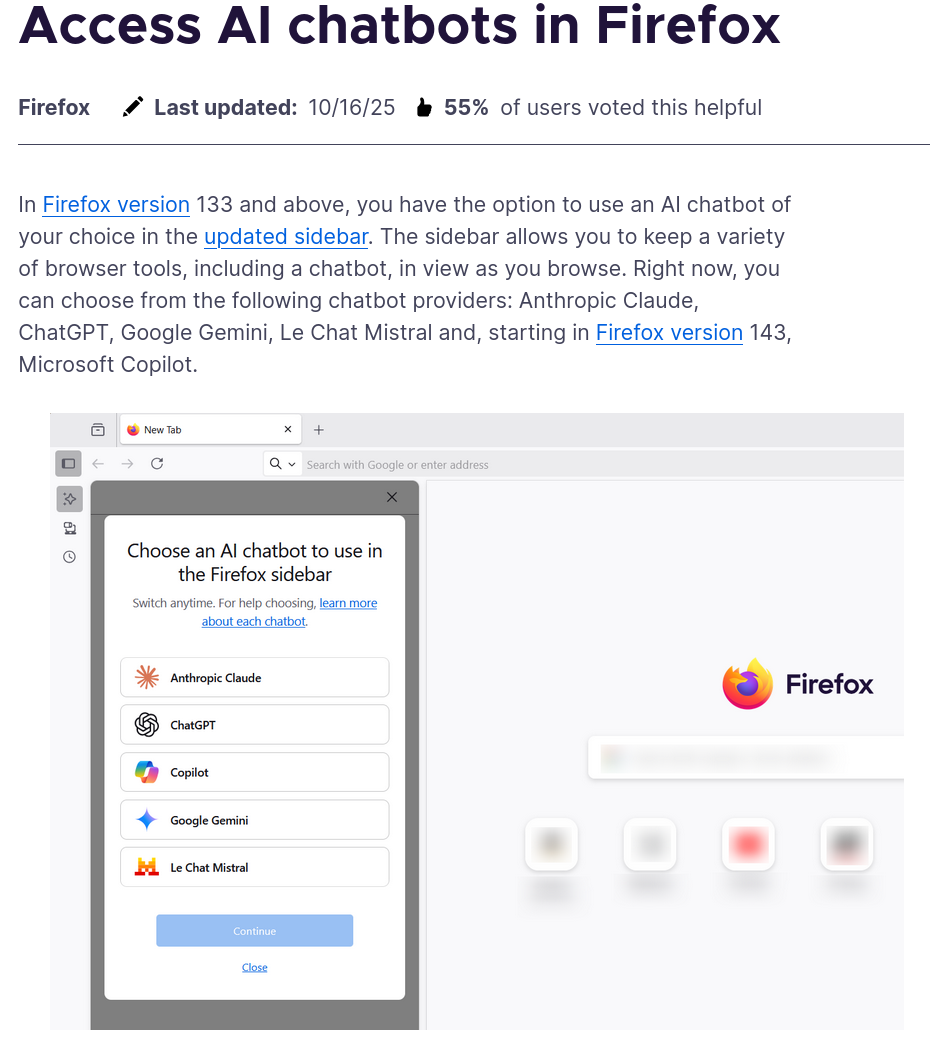
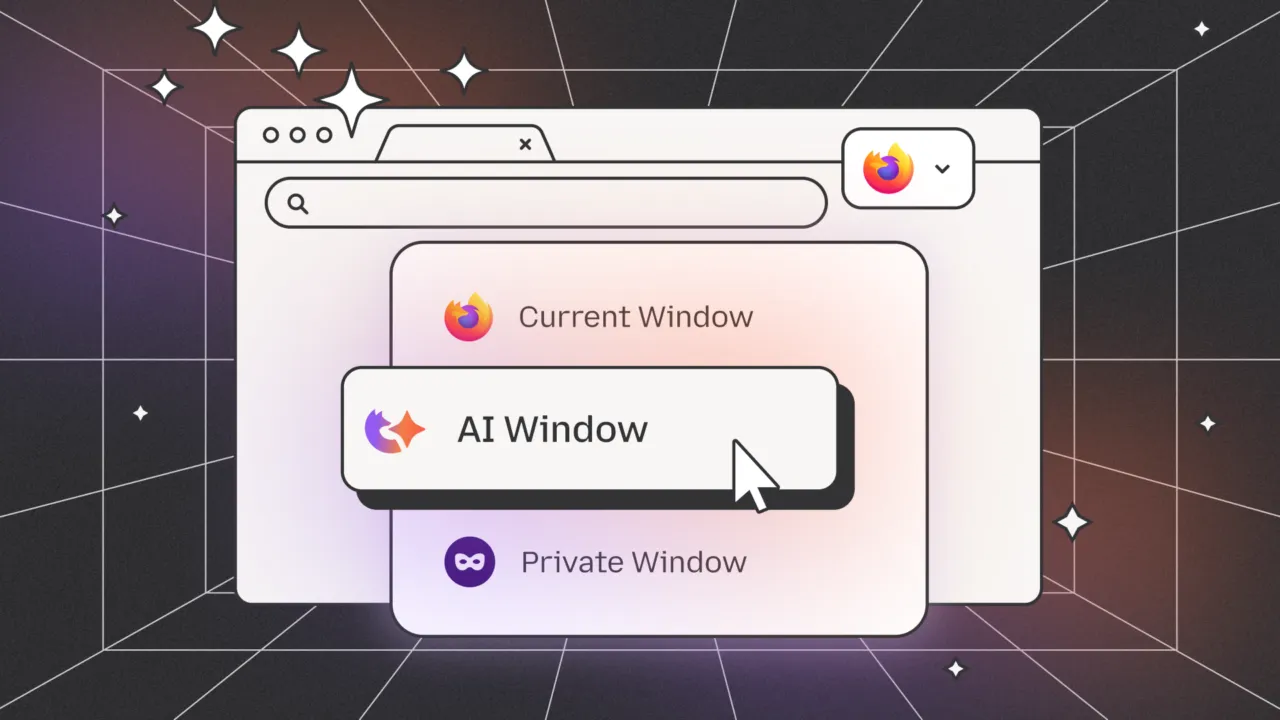
Finally, they want to take this a step further by creating "AI windows", where the AI assistant that you select will be able to interact with the webpage that you're seeing; though, this feature isn't publicly available yet.
It's interesting to see Mozilla try to strike a balance between being "modern and appealing" (to techbros!), but also not alienate their existing userbase. On one hand, I appreciate that most (if not everything) they are doing is opt-in and runs locally whenever possible. On the other hand, they'll still alienate a chunk of their users.
Since there was misinformation being spread around on this topic, I'd still like to stress that Mozilla in no way is collecting your data for anything related to AI training or selling it to AI companies. So at least there's that!
And, of course, Mozilla also has a dedicated subsidiary for AI.

All in all, with this article I tried to give a very brief overview of different approaches and reactions to AI-generated content within the FOSS world. As you can see, some projects are actively endorsing this change, some are being more cautious, and some are rejecting it outright.







{kind=link}