

Table of Contents
Three days ago, Drew DeVault - founder and CEO of SourceHut - published a blogpost called, "Please stop externalizing your costs directly into my face", where he complained that LLM companies were crawling data without respecting robosts.txt and causing severe outages to SourceHut.

I went, "Interesting!", and moved on.
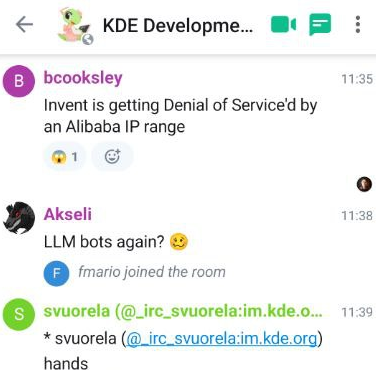
Then, yesterday morning, KDE GitLab infrastructure was overwhelmed by another AI crawler, with IPs from an Alibaba range; this caused GitLab to be temporarily inaccessible by KDE developers.
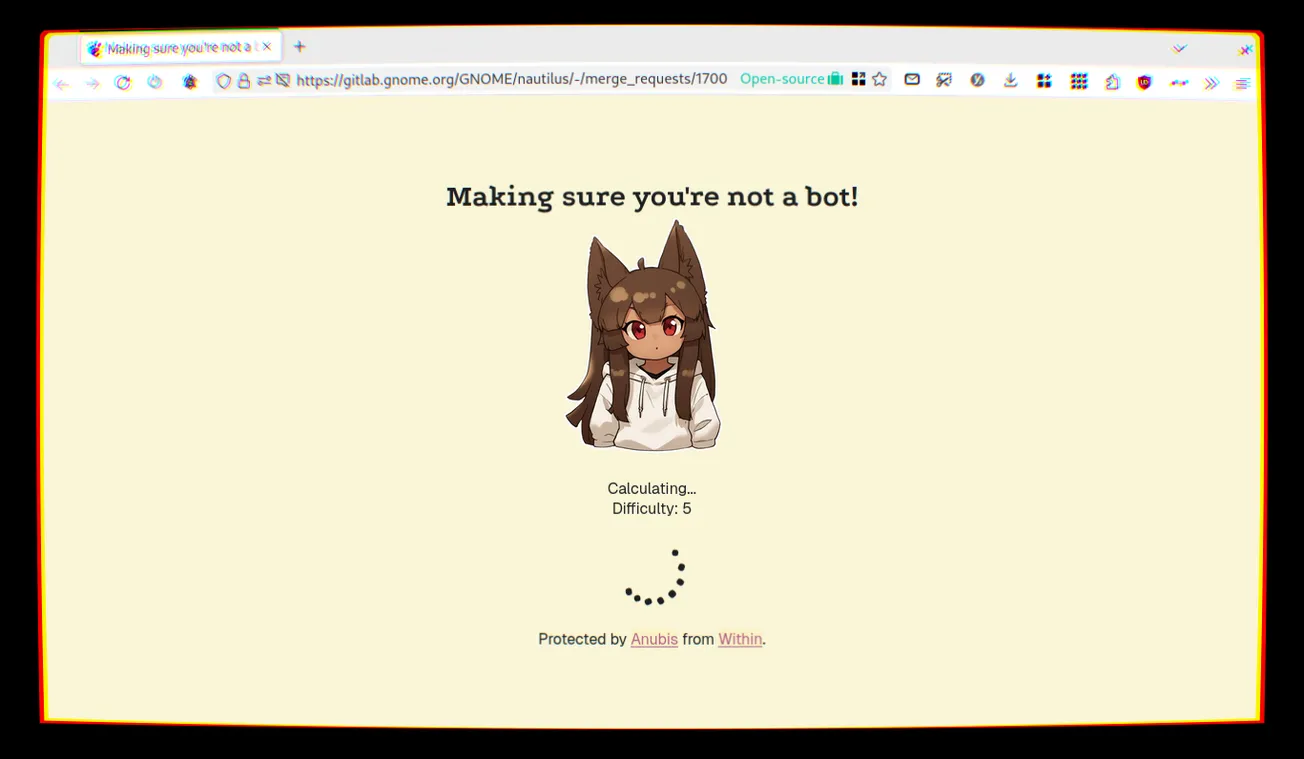
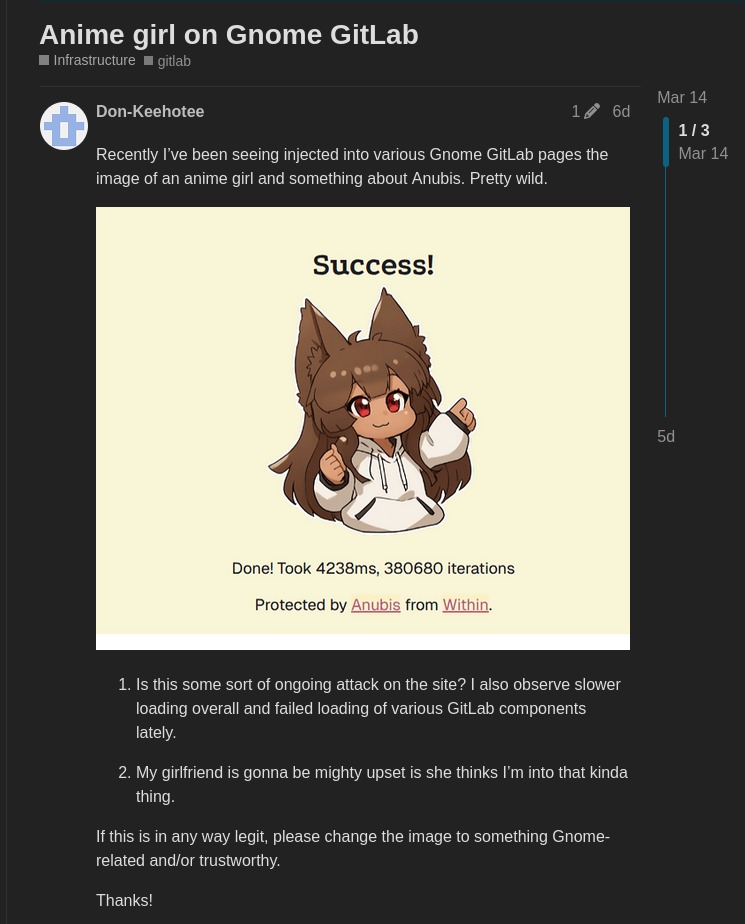
I then discovered that, one week ago, an Anime girl started appearing on the GNOME GitLab instance, as the page was loaded. It turns out that it's the default loading page for Anubis, a proof-of-work challenger that blocks AI scrapers that are causing outages.
By now, it should be pretty clear that this is no coincidence. AI scrapers are getting more and more aggressive, and - since FOSS software relies on public collaboration, whereas private companies don't have that requirement - this is putting some extra burden on Open Source communities.
So let's try to get more details – going back to Drew's blogpost. According to Drew, LLM crawlers don't respect robots.txt requirements and include expensive endpoints like git blame, every page of every git log, and every commit in your repository. They do so using random User-Agents from tens of thousands of IP addresses, each one making no more than one HTTP request, trying to blend in with user traffic.

Due to this, it's hard to come off with a good set of mitigations. Drew says that several high-priority tasks have been delayed for weeks or months due to these interruptions, users have been occasionally affected (because it's hard to distinguish bots and humans), and - of course - this causes occasional outages of SourceHut.

Drew here does not distinguish between which AI companies are more or less respectful of robots.txt files, or more accurate in their user agent reporting; we'll be able to look more into that later.
Finally, Drew points out that this is not some isolated issue. He says,
All of my sysadmin friends are dealing with the same problems, [and] every time I sit down for beers or dinner to socialize with sysadmin friends it's not long before we're complaining about the bots. [...] The desperation in these conversations is palpable.

Which brings me back to yesterday's KDE GitLab issues. According to Ben, part of the KDE sysadmin team, all of the IPs that were performing this DDoS were claiming to be MS Edge, and were due to Chinese AI companies; he mentions that Western LLM operators, such as OpenAI and Anthropic, were at least setting a proper UA - again, more on this later.
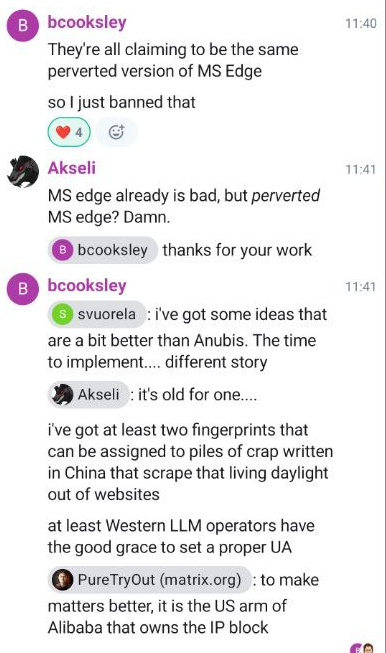
The solution - for now - was to ban the version of Edge that the bots were claiming to be, though it's hard to believe that this will be a definitive solution; these bots do seem keen on changing user agents to try to blend in as much as possible.
Indeed, GNOME has been experiencing issues since a last November; as a temporary solution they had rate-limited non-logged in users from seeing merge requests and commits, which obviously also caused issues for real human guests.
The solution the eventually settled to was switching to Anubis. This is a page that presents a challenge to the browser, which then has to spend time doing some math and presenting the solution back to the server. If it's right, you get access to the website.
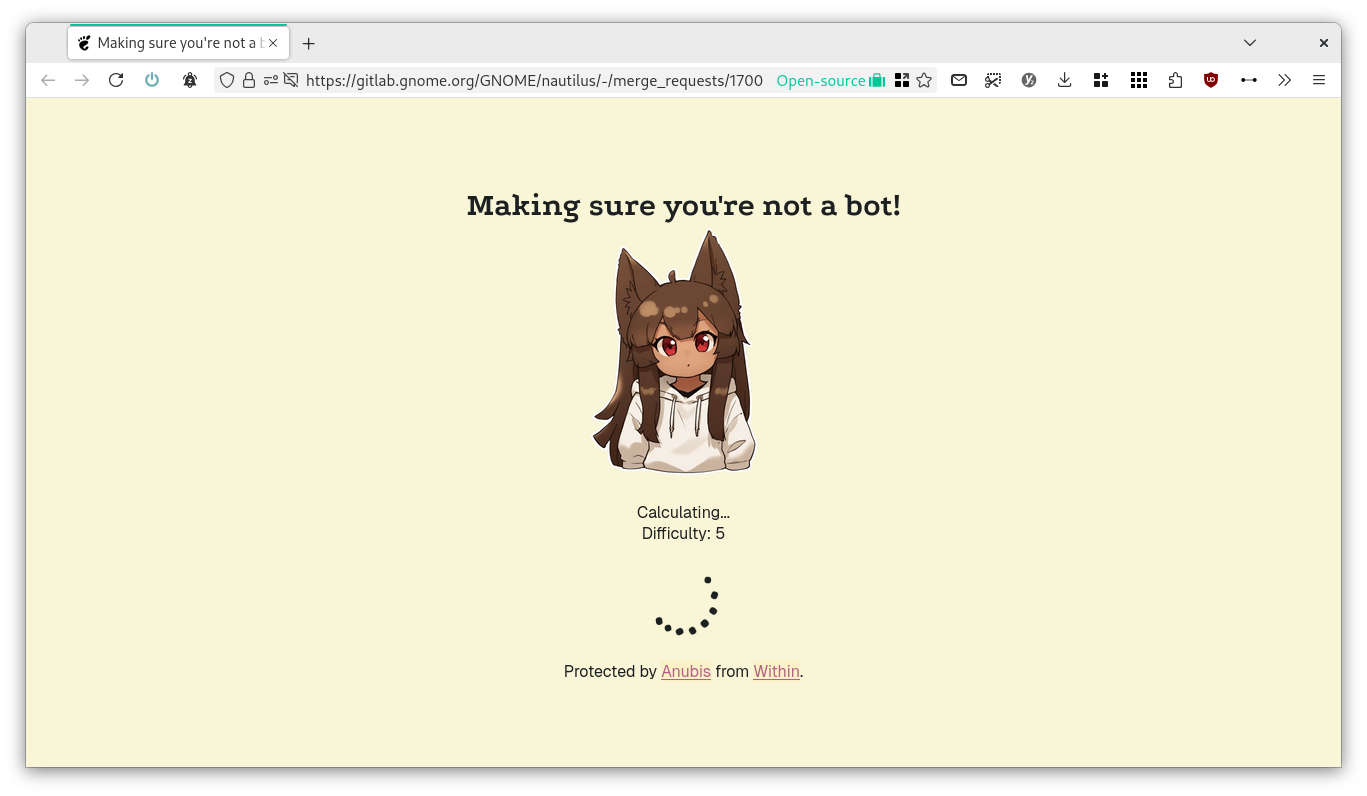
According to the developer, this project is "a bit of a nuclear response, but AI scraper bots scraping so aggressively have forced my hand. I hate that I have to do this, but this is what we get for the modern Internet because bots don't conform to standards like robots.txt, even when they claim to".
However, this is also causing user issues. When a lot of people open the link from the same place, it might happen that they get served some higher-difficulty exercise that will take some time to complete; there's one user reporting one minute delay, and another - from his phone - having to wait around two minutes.
Why? Well, a GitLab link was pasted in a chatroom! Similarly, the same happened when the Triple Buffering GNOME merge request was posted to Hacker News, and thus received a lot of attention over there. As the developer said, it's a nuclear option for crawlers, but it also has human consequences.
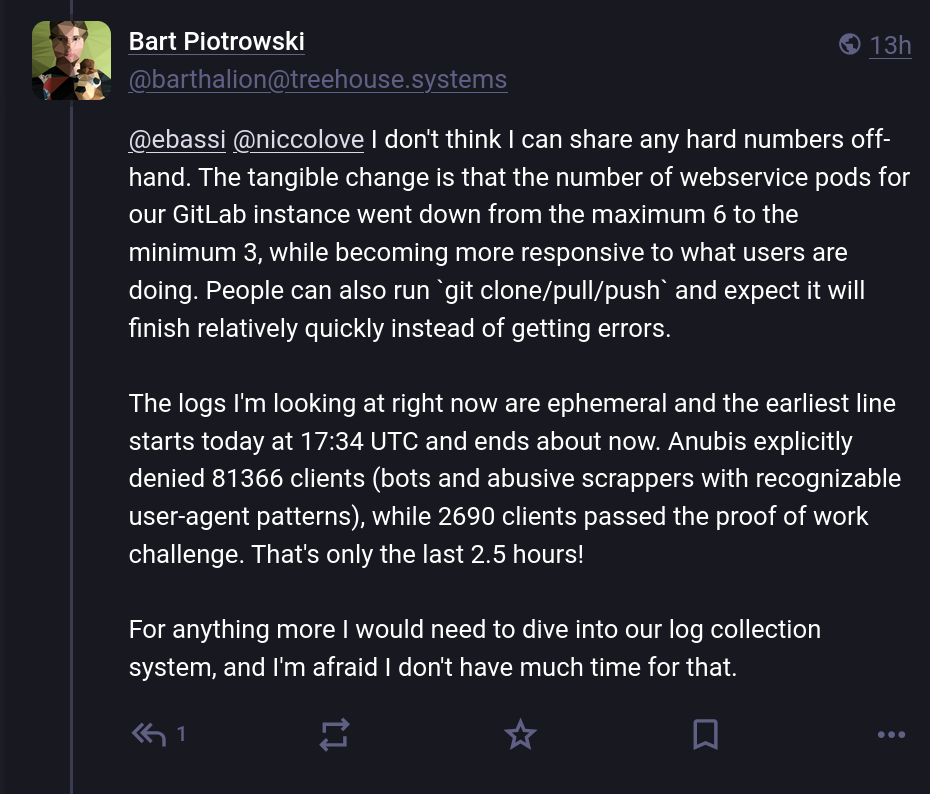
Over Mastodon, one GNOME sysadmin, Bart Piotrowski, kindly shared some numbers to let people fully understand the scope of the problem. According to him, in around two hours and a half they received 81k total requests, and out of those only 3% passed Anubi's proof of work, hinting at 97% of the traffic being bots – an insane number!
That said, at least that worked. Other organizations are having a harder time dealing with these scrapers.
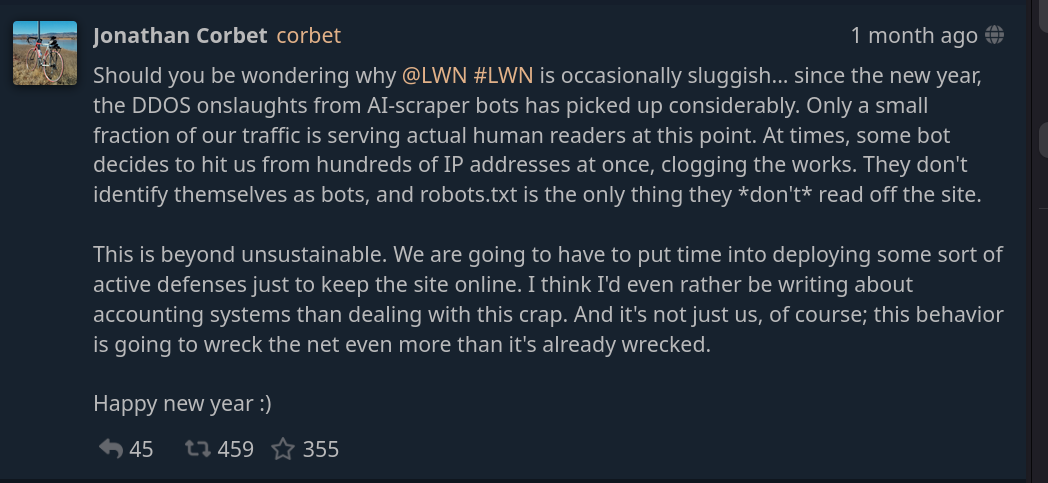
As an example, here's Jonathan Corbet, who runs the FOSS news source LWN, warns users that the website might be "occasionally sluggish"… due to DDoS from AI scraper bots. He claims that "only a small fraction of our traffic is serving actual human readers", and at some point, the bots "decides to hit us from hundreds of IP addresses at once. [..] They don't identify themselves as bots, and robots.txt is the only thing they don't read off the site".
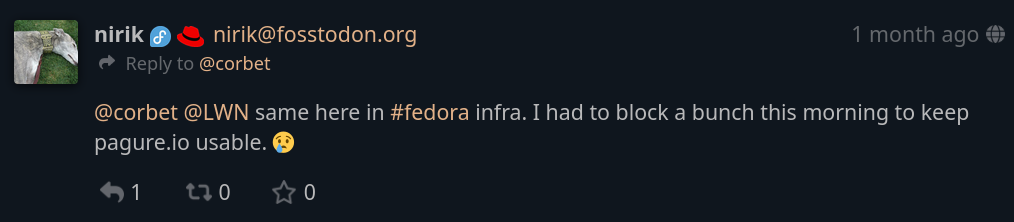
Many expressed solidarity, including Kevin Fenzi, sysadmin for the Fedora project. They've also been having issues with AI scrapers: firstly, one month ago they had to fight to get pagure.io to stay alive:
However, things got worse over time, so they had to block a bunch of subnets, which has also impacted many real users. Out of desperation, at one point Kevin decided to ban the entire country of Brazil to get things to work again; to my understanding, this ban is still in effect, and it's not so clear where a longer-term solution might be found.

And, as Neal Gompa points out, even this blocking an entire country only gets you so far, and apparently the Fedora infrastructure has been "regularly down for weeks" because of AI scrapers.
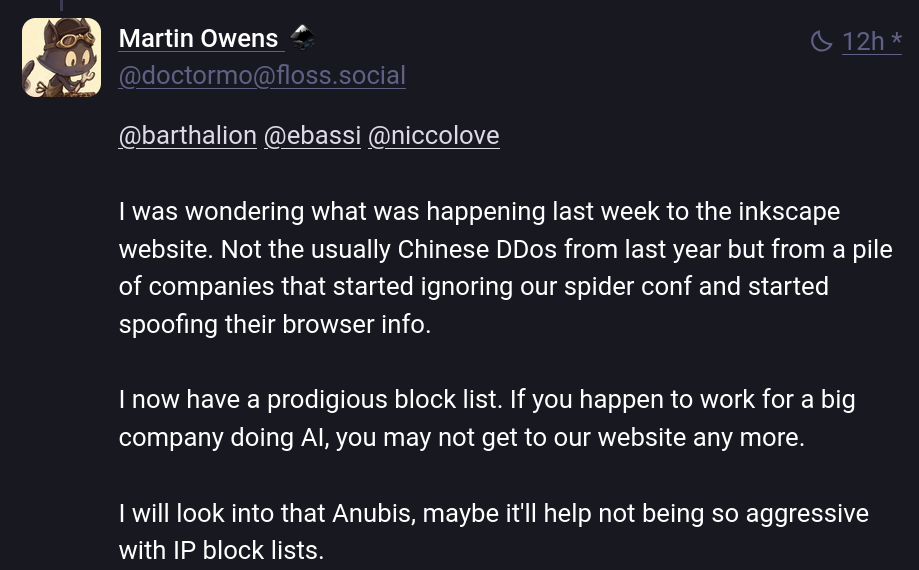
Another project that's been hit by this issue in the last week is Inkscape. According to Martin Owens, it's not "the usual Chinese DDoS from last year, but from a pile of companies that started ignoring our spider conf and started spoofing their browser info. I now have a Prodigius block list. If you happen to work for a big company doing AI, you may not get our website anymore".
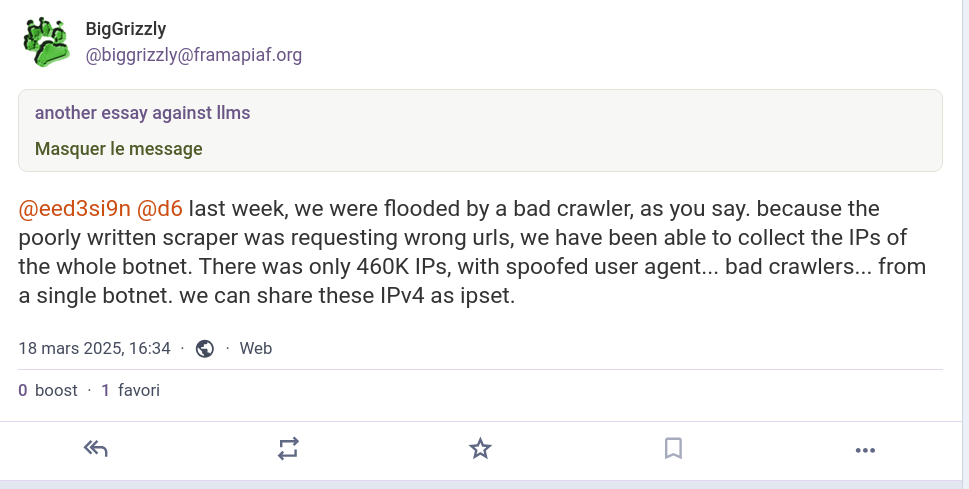
And, well, Martin is not the only developer who has built a "prodigious block list". Even BigGrizzly from Frama software was flooded by a bad LLM crawler, and built a list of 460K IPs with spoofed user agents to ban; he's offering to share the list around.
One more comprehensive attempt at this is the "ai.robots.txt" project, an open list of web crawlers associated with AI companies. They offer a robots.txt that implements the Robots Exclusion Protocol and a .htaccess file that will return an error page when getting a request from any AI crawler in their list.
We can get some more numbers about the crawlers if we go a few months back. Here's a post by Dennis Schubert about the Diaspora (an Open Source decentralized social network) infrastructure, where he says that "looking at the traffic logs made him impressively angry".
In the blogpost, he claims that one fourth of his entire web traffic is due to bots with an OpenAI user agent, 15% is due to Amazon, 4.3% is due to Anthropic, and so on. Overall, we're talking about 70% of the entire requests being from AI companies.

According to him,
they don’t just crawl a page once and then move on. Oh, no, they come back every 6 hours because lol why not. They also don’t give a single flying fuck about robots.txt, because why should they. [...] If you try to rate-limit them, they’ll just switch to other IPs all the time. If you try to block them by User Agent string, they’ll just switch to a non-bot UA string (no, really). This is literally a DDoS on the entire internet.
A similar number is given by the Read the Docs project. In a blogpost called, "AI crawlers need to be more respectful", they claim that blocking all AI crawlers immediately decreased their traffic by 75%, going from 800GB/day to 200GB/day. This made the project save up around $1500 a month.

The rest of the article is pretty impressive too; they talk about crawlers downloading tens of terabytes of data within a few days, or more. It's hard to block them entirely, since they use various different IPs.

I do wonder how much of this is scraping for training data, and how much instead is the "search" function that most LLMs provide; nonetheless, according to Schubert, "normal" crawlers such as Google's and Bing's only add up to a fraction of a single percentage point, which hints at the fact that other companies are indeed abusing their web powers.
But it's not just scrapers, or I would've titled this "AI scrapers", not "AI companies". Another issue that Open Source community have been fighting with is AI-generated bug reports, as an example.
This was first reported by Daniel Stenberg of the Curl project, in a blogpost titled "The I in LLM stands for Intelligence". Curl offers a bug bounty project, but lately, they've noticed that many bug reports are generated by AI. These look credible and take up a lot of developer time to check, but they also contain the typical hallucinations you'd expect from AIs.
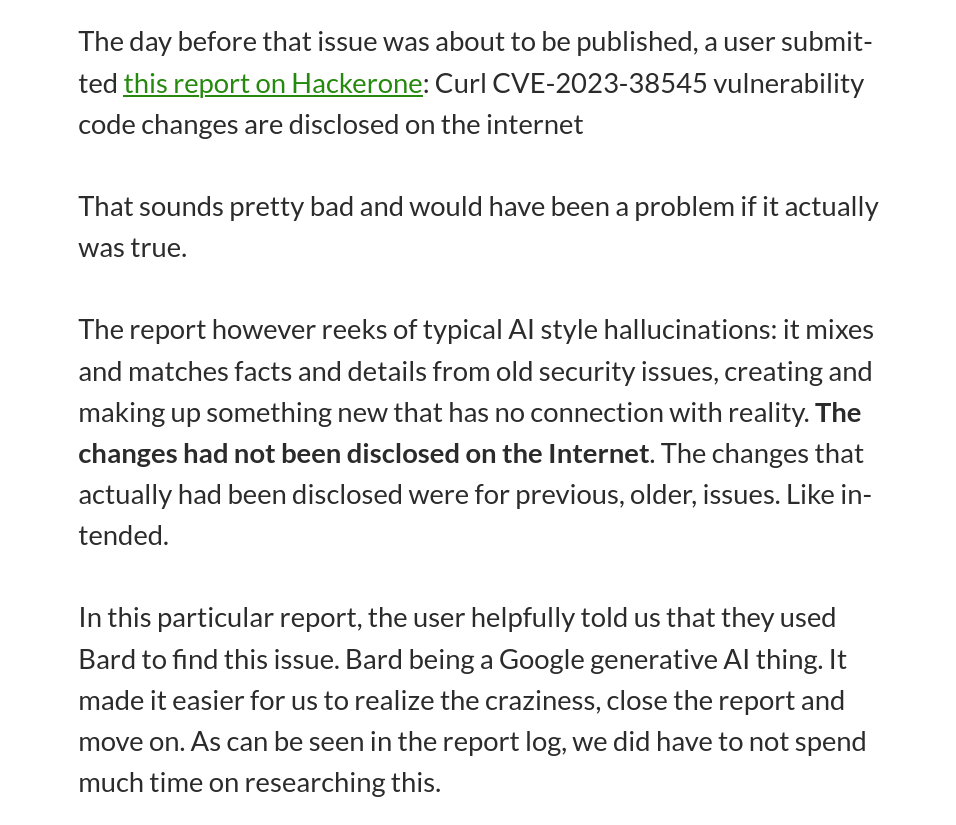
It's pretty crazy to have to go through your own code because a bug report confidently tells you there's some critical security issue to fix, and … not finding it, because the whole issue is just AI hallucination.

A similar issue was reported by Seth Larson, who's on the security report triage team for CPython, pip, urllib3, Requests, and more. He says,
Recently I've noticed an uptick in extremely low-quality, spammy, and LLM-hallucinated security reports to open source projects. The issue is in the age of LLMs, these reports appear at first-glance to be potentially legitimate and thus require time to refute.

This is a pretty big issue. As he points out, responding to security reports is expensive, and responding to invented but credible bug reports causes some significant additional burden on maintainers, which might drive them out of the Open Source world.

The article ends with a request: please, do not use AI or LLM systems for detecting vulnerabilities. He says, "These systems today cannot understand code, finding security vulnerabilities requires understanding code AND understanding human-level concepts like intent, common usage, and context.".

Again, I want to point out that these issues impact disproportionately on the FOSS world; not only do Open Source projects often have less resources compared to commercial products, but - being community-driven projects - much more of their infrastructure is public and thus susceptible to both crawlers and AI-generated bug reports or issues.




{kind=link}