


Table of Contents
A few weeks ago, a proposal was made for the Servo project to allow for AI contributions, which are currently prohibited. The proposal comes with strict guidelines: only allow for code completion like Copilot, tag all AI contributions as so, and more.
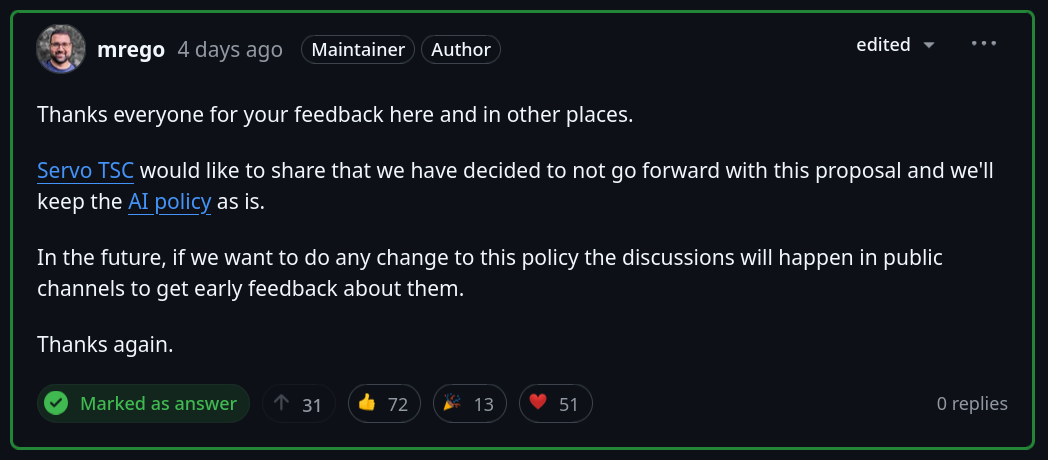
After a few weeks of intense discussion, the Servo Technical Steering Committee decided not to go forward with the proposal and keep their AI policy as it is now.
Namely, this policy states that all contributions "must not include content generated by LLM or other probabilistic tools, including but not limited to Copilot or ChatGPT". This cover both code and documentation.

You might be wondering why they have decided to take this path. It comes down to four reasons.
Firstly, AI makes it easy to generate lengthy but incorrect diffs, which the contributor might not check or test. It becomes then the maintainers' responsibility to go through them and realize they are incorrect.

Secondly, code generated by AI has no guarantee of being correct, and it might have security issues. Again, contributors using AI tools might not be able (or want) to catch those manually.

Thirdly, copyright. We know that these large models are trained on copyrighted content, and Servo claims that their output often includes that content verbatim, which would expose Servo to potential legal headaches.

Finally, there are ethical issues. According to Servo, AI models require an "unreasonable amount of energy and water to build and operate, their models are built with heavily exploited workers in unacceptable working conditions, and they are being used to undermine labor and justify layoffs". The project does not want to perpetuate that, even indirectly.

What's interesting is that Servo is not the only project that takes this stance, but an increasing amount of repositories are now off-limits for AI generated code.
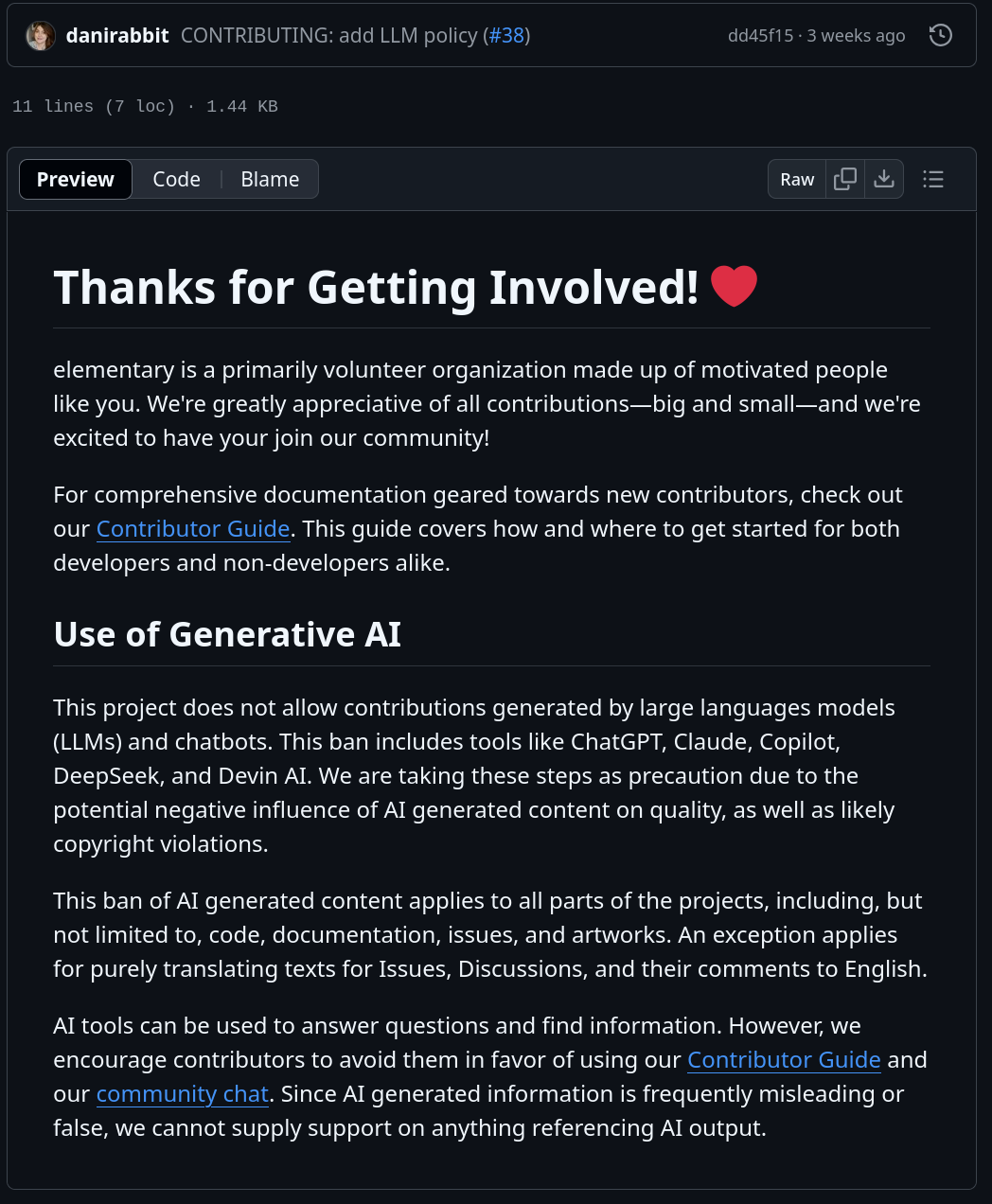
As an example, Loupe, GNOME's image viewer application, also recently added a section about Generative AI on their contribution guidelines.
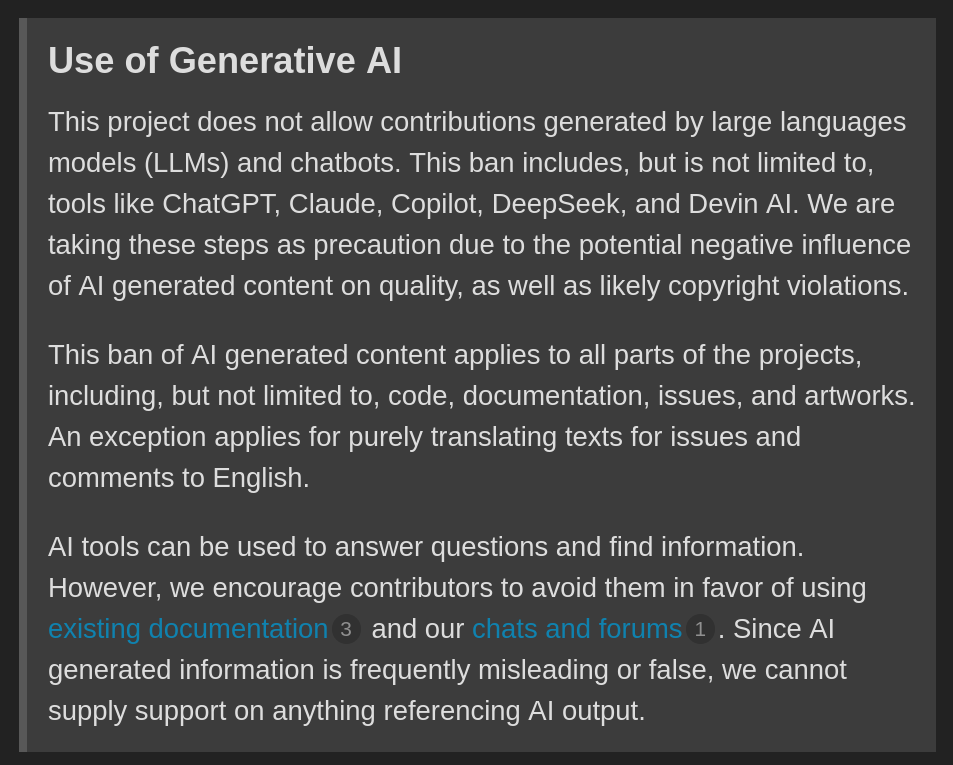
This policy states, and I quote,
This project does not allow contributions generated by large language models and chatbots. [..] We are taking these steps as precaution due to the potential negative influence of AI generated content on quality, as well as likely copyright violations. This ban of AI generated content applies to all parts of the projects, including, but not limited to, code, documentation, issues, and artworks.
A month later, this guideline was added by Alice to: GNOME's app Elastic, libadwaita, libmanette, libhighscore, and the Highscore application. I wouldn't be surprised to see this list grow over time.
Three weeks ago, ElementaryOS also added the same policy, directly taken from Loupe's. AI code is a no-go there, too.
Other older examples of this are NetBSD, which explicitly states that code generated by LLMs "is presumed to be tainted code and must not be committed without prior written approval by core."

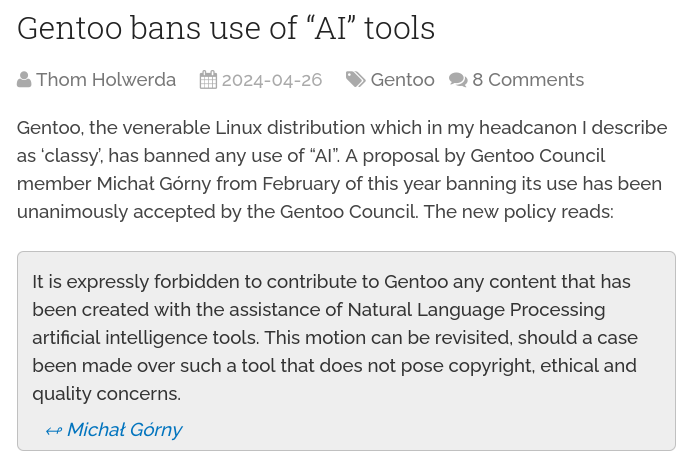
Finally, there's Gentoo: "It is expressly forbidden to contribute to Gentoo any content that has been created with the assistance of Natural Language Processing artificial intelligence tools".
Let's discuss this decision on its merits. I want to firstly point out the obvious, and address the very first question that was raised on each of these discussions: how will they know what code is AI-generated?
The answer is that there's no way to know for certain: all of these guidelines above are entirely unenforceable. A few people claimed that they "can tell" whether a large contribution is made by AI, and I do believe that we can mark some contributions as most likely written with those tools, but I also believe that we cannot ban people on "most likely" considerations or personal intuitions. Either the author admits to AI usage, or this request is entirely based on trust between the contributor and the project.
Though, as Sophie points out, the same applies to people owning the code they are submitting: there's no way for a certain project to check whether the submitted code isn't just stolen by the contributor from elsewhere.
Personally, I'm not completely sold on this equivalence. When I submit code to an open-source project, I'm taking (legal!) responsibility for it, and if it's stolen, I'll get in trouble; it does not, however, limit how I can write that code. Instead, the AI section is trying to limit the kind of tools I can use to write my code, such as whether I can use autocompletion, and this is a much stronger request.
I'm not even convinced that a project has the right to make this request to the contributor. To make an example, if there were a text editor that was sponsored by fascists and whose owner said some disgraceful things, would the project be justified in prohibiting contributors from using that text editor to write the code? I believe not, as it should instead be a choice of the contributors themself (though, they can ask).
As another user points out in the Loupe discussion, the kind of person who will contribute large patches entirely generated by AI is most likely also the kind of inexperienced contributor that's willing to ignore Contributor guidelines. And, if they do ignore the guideline, there won't be any way to punish them, as there's no way to know for sure that the code is AI-generated (and you certainly don't want to ban people by mistake).

From the same thread, Emmanuele Bassi adds that "the only people that end up using LLMs are people that are not learning to code but want to submit something anyway".
I also take issue with this claim. Though I won't deny that there are plenty of people who do use AI tools to avoid learning a certain language, I also see plenty of already-skilled people use it to speed up their workflow, myself included.
As an example, I've used Python throughout my whole life, and I have given multiple talks at PyCon about the language and some of its more obscure aspects. I'm not a great Python developer, but I can quickly get things done using it. That said, I often use AI to generate parts of some Python scripts, because it's easier and it gets it right most of the time; it's significantly faster for me to check that something is written correctly than to write it myself from scratch, and I can always make my changes to the code where I think it's needed.
Of course, since I do know Python, I make sure that the generated code makes sense and works properly. All code that I submit to any project is code that I would've written like that, and I take full responsibility for it. I won't deny the existence of people who just copy-paste code from ChatGPT without having a clue what it means, of course.
But what about all the other claims? Legal issues, the impact on climate change, and more?
Legally speaking, unless there are other contributor agreements in place (or employment situation), all contributors preserve the ownership of their contributions to open source projects. If it turns out that a certain piece of code was stolen by the contributor, they will be the ones who will get in trouble for it. To the best of my knowledge (I'm not a lawyer!), the same would happen if the code submitted by the contributor turned out to be taken as-is from another project. This means that the decision of whether to take this legal risk or not falls on the shoulders of the contributors, and not of the project, which would be unaffected.

I believe that the same applies to the ethical and climate issues of AI tools; though it's important to raise awareness of their problems, I believe it's ultimately the contributors' choice on whether to use these tools despite that. Again, I decide to use AI tools because I'm currently convinced that the claims about climate impact are overblown, and I believe that using copyrighted material for training is fair use, though I do take issue with the usage of underpaid third-world workers for alignment (and, of course, I'm willing to change my mind if presented with more evidence). I think that this should be ultimately my choice (or, at worst, my employer's choice) instead of the project I'm contributing to.
Really, since I believe they don't have legal responsibilities of it, I believe the only impact that the project has to deal with is the additional maintainer's burden of reviewing completely bogus AI merge requests, which do exist. However, I also believe that this policy will be entirely ineffective at stopping this, for the reasons explained above.

Going further, I'm a bit shocked by some of the replies that the Servo proposal of allowing for just AI autocompletion in code received.
As an example, user "multiplealiases" wrote that "A good chunk of people [...] are going to see this and consider servo tainted. Merely entertaining AI these days is a statement, and that statement is "we don't care about quality, we don't care about contributors, all hail the slop machine".
If you think about it, this statement is pretty shocking: almost all of the open source projects currently have no guidelines for AI, only a few ones do. By this logic, the entire open source world, with only a handful of exceptions, is tainted.
The same applies to developer mcclure, who would've stopped donating and contributing to the project if the proposal had been approved, as they "will not contribute code on a project where you don't know if code you are interacting with [..] was written by a human or randomly generated".
Again, this means not donating nor contributing to the entirety of open-source, with only a few exceptions. It seems to me like these comments completely fail to take in account the broader context of the open-source world, where AI contributions are currently accepted almost everywhere.
This is to be found throughout the thread. Even though the proposed AI policy would still be significantly more strict than almost every other open-source project, since it only allows for code completion and requires tagging of AI-generated code, people would be considering Servo as actively "embracing AI".
There's even someone who says that they will never use Servo because it contains AI-generated code; which, again, forgets how the vast majority of open-source projects, even open-source ones, contain AI-generated code by now.
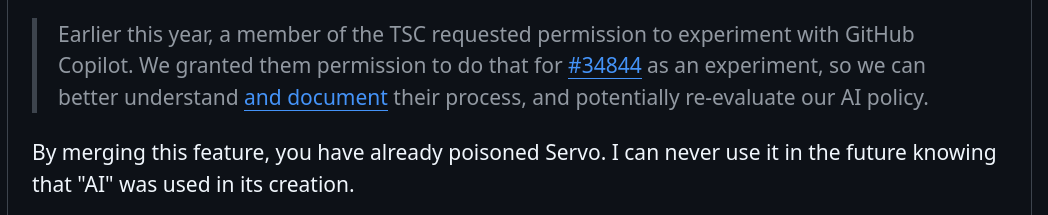
Of course, the overwhelmingly negative feedback on the proposal eventually prompted the Technical Steering Committee to change their minds and not go forward with it.
Though I can understand hostility towards AI tools, and I'm frustrated myself by the over-promises and the hype bubble, I nonetheless think there's a lot of irrationality when discussing it. A good example, in my opinion, is the video by The Linux Experiment where he says he'd ditch Firefox. Though the fundamental issue was a lack of understanding of the actual policy changes, he started saying that he did not trust Mozilla anymore, as he believed they'd start selling data to AI companies, though there was no evidence of that whatsoever. It was completely irrational.
I also believe it is a bit irrational to try to force contributors to avoid specific tools when there's no way to enforce that or ever ban a bad actor who would lie about using them, and I think it would be more useful to continue to advocate against AI through other means.




{kind=link}